
da Hardware Upgrade :
L’utilizzo dell’intelligenza artificiale nei datacenter non è ormai più una novità: da tempo queste tecniche sono a servizio del’HPC, High Performance Computing, per accelerare le elaborazioni e permettere di gestire in parallelo una mole di informazioni sempre più importante. D’altro canto sono le soluzioni hardware del mondo HPC ad essere ora pensate nell’ottica di velocizzare le tecniche di intelligenza artificiale: questo lavoro congiunto permette di ridurre i tempi di elaborazione, o a parità di tempo impiegato di eseguire elaborazioni sempre più complesse e sofisticate. Chi esegue il training dei modelli di intelligenza artificiale, del resto, sono i supercomputer tipici del mondo HPC per i quali è richiesta continua innovazione.
Da questa interdipendenza tra sistemi HPC ed elaborazioni di intelligenza artificiale deriva una struttura differente dei sistemi HPC rispetto a quelli AI. I primi vedono l’utilizzo in numeri elevati di CPU, affiancate all’interno dei singoli nodi da un numero di GPU che può essere fino a 4 o superiore a seconda delle specifiche esigenze e implementazioni. I secondi, invece, sono molto più sbilanciati verso l’integrazione di GPU per accelerare alcune operazioni, con la maggior parte dei nodi che ne integrano ben 8, oltre alla presenza di acceleratori custom per l’intelligenza artificiale.
Il futuro vede quindi una interazione sempre più forte tra il mondo dell’HPC e quello dell’intelligenza artificiale, responsabili della futura direzione del mercato. Per arrivare a tutto questo il mercato si muove verso lo sviluppo incentrato sui due elementi chiave: hardware e software. In occasione dell’ISC di Amburgo, evento sul mondo dei Supercomputer che si sta tenendo in questi giorni, Intel ha anticipato molte delle novità che vedremo al debutto dei prossimi anni mostrando la propria roadmap delle soluzioni cosiddette Data Center Silicon, che comprendono core CPU, acceleratori dedicati all’intelligenza artificiale e ovviamente GPU.
La roadmap Intel per le soluzioni datacenter prevede una ricca famiglia di soluzioni CPU Xeon, affiancate da acceleratori per l’intelligenza artificiale della famiglia Gaudi oltre all’immancabile pacchetto di GPU Max Series, tanto per la parte visual come per il calcolo in AI unitamente alle soluzioni custom FPGA pensate per ambiti di elaborazione verticali e specifici. Due sono gli aspetti da tenere in considerazione: il primo riguarda le soluzioni Gaudi per l’IA, con quella Gaudi 2 ora disponibile e quella Gaudi 3 che arriverà sul mercato nel corso del 2024. Il secondo è l’evoluzione delle GPU, con le proposte della famiglia Ponte Vecchio a disposizione dei differenti partner Intel che verranno sostituite nel 2025 con la prossima generazione di GPU nota con il nome in codice di Falcon Shores.

Dall’attuale generazione di processori Intel Xeon in commercio passeremo per il quarto trimestre 2023 alla quinta generazione di piattaforma Intel Xeon Scalable, nota con il nome in codice di Emerald Rapids: queste CPU adotteranno la tessa piattaforma ora in commercio con un miglioramento delle prestazioni a parità di consumo. L’evoluzione successiva, attesa per il 2024, è quella indicata con il nome in codice di Granite Rapids: avremo un incremento nel numero di core per socket, nel quantitativo di memoria e nella gestione dell’I/O grazie anche all’utilizzo per la prima volta per i P-Core Xeon della tecnologia produttiva Intel 3.

La gamma attuale vede la presenza dei processori Intel Xeon Max, dotati sullo stesso package dei core anche di 64GB di memoria HBM2e con 4 stack da 16GB di capacità ciascuno. Si tratta di CPU pensate specificamente per quegli ambiti di utilizzo nei quali l’incremento nel numero dei core di ogni processore richiede anche il supporto di un quantitativo di bandwidth della memoria che sia altrettanto alto, così da garantire che non ci siano colli di bottiglia evidenti.

Proprio per rendere i sistemi sempre meno dipendenti dalla bandwidth della memoria, sfruttando in questo modo al meglio la disponibilità di un maggior numero di core per ogni processore, Intel annuncia quest’oggi le memorie MRC DIMM (Multiplexer Combined Ranks DIMM), che permettono di raggiungere sulla carta un raddoppio della bandwidth rispetto a quanto accessibile con la memoria DDR5 al momento attuale. A questo risultato si giunge grazie alla possibilità di accedere a due banchi in parallelo per ogni modulo, gestendo il tutto con un buffer montato su ogni singolo modulo DIMM.

Intel Gaudi 2
Intel propone con le soluzioni della famiglia Gaudi degli acceleratori specifici per gli ambiti di intelligenza artificiale. Al momento attuale è disponibile la soluzione Gaudi 2, che attraverso un design a chiplets costruito con tecnologia produttiva a 7 nanometri integra 24 tensor processor cores abbinati a 96GB di memoria HBM2 onboard, 48MB di memoria SRAM e ben 24 porte Ethernet integrate. La prossima generazione di acceleratore per applicazioni di AI, Gaudi 3, è previsto al debutto nel corso del prossimo anno: quello che si può immaginare come sviluppo futuro è una progressiva integrazione delle funzionalità di accelerazione delle soluzioni Gaudi all’interno delle GPU Intel, ma l’azienda almeno per il momento non ha indicato quando questo avverrà.

Falcon Shores è il nome in codice utilizzato da Intel per indicare la prossima generazione di GPU per i datacenter. Originariamente questo prodotto avrebbe dovuto integrare CPU e GPU in un singolo package ma Intel ha scelto di mantenere, almeno per il momento, queste due tipologie di unità di elaborazione separate. Questa decisione, che ha di fatto portato ad una profonda revisione della roadmap di Intel rispetto a quella di 12 mesi fa, è legata ai profondi cambiamenti avvenuti nel settore dell’HPC con la diffusione di sistemi che sfruttano al massimo l’intelligenza artificiale: si pensi a come ChatGPT abbia trasformato le modalitò di interazione di uan larga parte di consumatori e da questo modificato in misura marcata le necessità di elaborazione dei datacenter.
Falcon Shores è quindi il nome della prossima generazione di GPU della famiglia Max, che riproporrà l’architettura di tipo Tile-Based affiancata da memoria HBM3 e da una nuova tipologia di I/O pensata per migliorare la scalabilità delle prestazioni. Verrà ovviamente mantenuto l’approccio scalabile basato su differenti tile montati sullo stesso package, caratteristica che permette di sfruttare al meglio differenti tecnologie produttive in funzione dello specifico tile che si vuole implementare. Tutto questo richiede ovviamente grande sforzo sulle tecnologie di interconnessione, fondamentali per garantire una comunicazione che sia efficiente e non rappresenti un collo di bottiglia alle prestazioni.
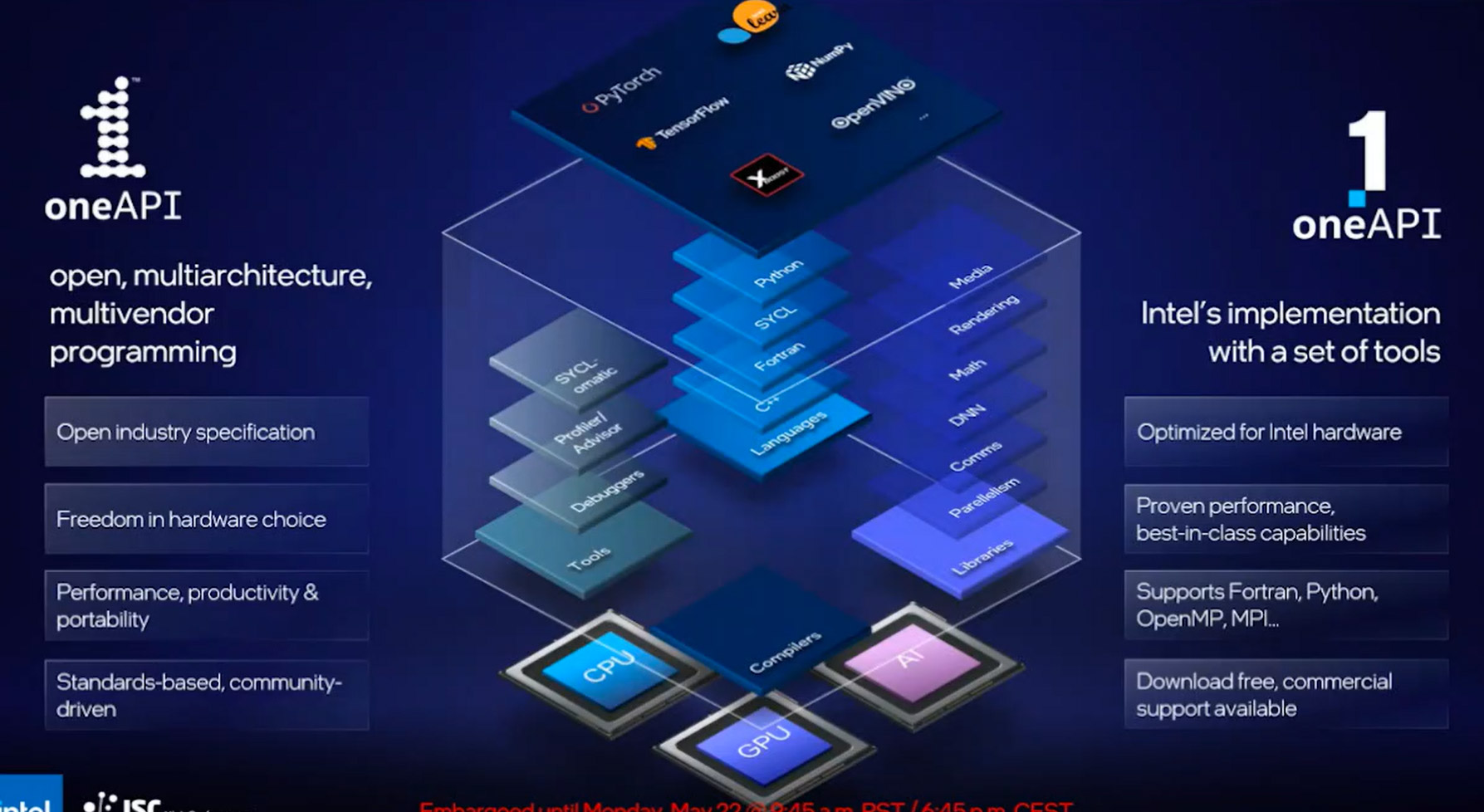
Nei sistemi di calcolo troviamo CPU, GPU e acceleratori AI: tutte queste tipologie di componenti interagiscono con una componente software. Per questo motivo un approccio unificato e open della componente software permette di sfruttare al meglio ogni risorsa di elaborazione sia presente nel datacenter. Per Intel la risposta a questa necessità è data da oneAPI, che ha dalla sua quale punto di forza la compatibilità con le differenti piattaforme hardware in commercio, anche se sviluppate dalla concorrenza. OneAPI è una iniziativa open, pensata sin dalle origini per operare con tutte le tipologie di architettura hardware così da essere facilmente sfruttabile da qualsiasi sviluppatore a prescindere dal tipo di piattaforma utilizzata.
Unificare lo stack software è per Intel un approccio di design che non può essere evitato, ma che anzi deve guidare l’intera industria nel suo complesso. Del resto sviluppare hardware custom per specifici ambiti di utilizzo è fantastico per i produttori di hardware, ma un incubo per i programmatori che devono adattare il loro codice alle differenti architetture hardware. Questo non vuol dire che non si possa arrivare a soluzioni che integrino più componenti, come GPU e CPU o GPU e acceleratori per AI, ma questa unificazione può arrivare in tempi differenti a seconda delle necessità del mercato. E’ addirittura possibile che l’evoluzione tecnologica, che in un momento conduce all’integrazione tra differenti componenti, possa ritornare ad un approccio con componenti discreti perché l’implementazione di nuove tecnologie e i livelli di potenza che queste richiedono porta in modo naturale a separare e non più a unificare i componenti tra CPU, GPU e acceleratori per intelligenza artificiale.

Una delle migliori implementazioni delle più recenti architetture Intel è in Aurora, sistema che al momento integra 10.624 nodi in ciascuno dei quali sono presenti due processori Xeon e 6 GPU della famiglia Max, il tutto collegato attraverso una struttura di Fabric Dragonfly che assicura elevata bandwidth di interconnessione tra i diversi nodi. E’ questo per l’azienda americana un esempio di come sia possibile ottenere elevata efficienza abbinando differenti soluzioni hardware e al contempo sfruttando i vantaggi di un approccio software unificato come quello ottenibile con oneAPI.

GPU Intel Ponte Vecchio in package per clienti OEM
L’evoluzione dei datacenter sta avvenendo, per molti versi, ad un ritmo ancora più rapido di quanto sperimentato nel recente passato: il mercato cambia con maggiore velocità e con esso vengono a mutare le necessità delle differenti aziende. Basti pensare alla rivoluzione rappresentata da ChatGPT negli ultimi mesi e a quanto la sua diffusione in ambito consumer abbia generato conseguenze radicali nel settore dei datacenter per capire la difficoltà di pianificare soluzioni hardware che siano allineate a quelle che saranno le necessità di elaborazione del prossimo futuro. E’ per questo motivo che, ad esempio, Intel ha rivisto la propria roadmap delle GPU con Falcon Shores scartando, almeno per il momento, una strada di integrazione tra CPU e GPU in un singolo prodotto per il datacenter.
Quello che è emerso all’ISC di Amburgo è non solo quanto sia difficile pianificare al meglio le singole soluzioni hardware che dovranno essere rese disponibili ai clienti nel futuro, ma anche quanto il naturale processo di integrazione di diverse unità di elaborazione in singoli componenti possa mutare nel tempo. La distinzione tra componenti discreti e integrati muta nel tempo: quando una nuova tecnologia viene resa disponibile questa è inizialmente in forma discreta e solo in un secondo tempo viene integrata (si pensi alle GPU prima dicrete e poi integrate nelle CPU). E’ però possibile che il debutto di nuove tecnologie ritorni ad un approccio con componenti discreti, che solo in un secondo tempo verranno integrati.
Accanto alle possibilità offerte dalla tecnologia dobbiamo anche tener conto delle necessità dei clienti: in alcuni casi avere componenti integrati permette di ottimizzare l’efficienza, ma in altri appoggiarsi a design discreti permette di massimizzare le prestazioni di specifici pattern di utilizzo. Del resto in una singola CPU, ad esempio, si possono integrare un massimo di tot acceleratori: un approccio discreto permette invece di adattare questo rapporto tra i componenti in funzione di quanto realmente necessario per lo specifico ambito di utilizzo. Sono queste considerazioni che spingono le roadmap dei prodotti in una direzione o nell’altra, ferma restando la necessità di un software stack condiviso e di facile applicabilità che sfrutti tutte le soluzioni hardware sviluppate di volta in volta dalle varie aziende che operano nel settore dei supercomputer.