
da Hardware Upgrade :
Gli Intel Labs hanno messo a punto due nuovi modelli AI per la computer vision chiamati VI-Depth 1.0 e MiDaS 3.1. I due nuovi modelli, open source con licenza MIT, sono disponibili su GitHub (qui e qui) e puntano a migliorare la “depth estimation“, cioè la stima della profondità.
Che si tratti di robotica, realtà aumentata o virtuale, la stima della profondità è un compito di computer vision complesso ma essenziale in un’ampia gamma di applicazioni. Le attuali soluzioni spesso faticano a stimare correttamente le distanze, un elemento cruciale per qualsiasi tecnologia robotica che deve muoversi in uno spazio ed evitare ostacoli basandosi sulla navigazione visiva.
In soccorso della comunità degli sviluppatori arrivano i ricercatori degli Intel Labs con due modelli AI dedicati alla stima di profondità: una dedicato alla “visual-inertial depth estimation” e uno alla “robust relative depth estimation” (RDE).
L’ultimo modello RDE, MiDaS 3.1, usa una sola immagine come input. Grazie alla sua formazione su un set di dati ampio e diversificato, può adattarsi in modo efficiente a una gamma più ampia di attività e ambienti. L’ultima versione di MiDaS migliora la precisione del modello per RDE di circa il 30%.
MiDaS è stato incorporato in molti progetti, in particolare Stable Diffusion 2.0, dove abilita la funzione depth-to-image che deduce la profondità di un’immagine di input e quindi genera nuove immagini usando sia il testo che le informazioni sulla profondità.
Ad esempio, il creator Scottie Fox ha usato una combinazione di Stable Diffusion e MiDaS per creare un ambiente VR a 360 gradi. Questa tecnologia potrebbe portare a nuove applicazioni virtuali, tra cui la ricostruzione della scena del crimine per casi giudiziari, ambienti terapeutici per l’assistenza sanitaria ed esperienze di gioco immersive.
Quanto a RDE, sebbene abbia una buona generalizzabilità, la mancanza di scala ne riduce l’utilità in quelle attività che richiedono profondità metrica, come la mappatura, la pianificazione, la navigazione, il riconoscimento di oggetti, la ricostruzione 3D e l’editing di immagini. I ricercatori degli Intel Labs stanno affrontando questo problema con VI-Depth, un altro modello di intelligenza artificiale che fornisce una stima accurata della profondità.
VI-Depth è una pipeline visiva-inerziale per la stima della profondità che integra la stima della profondità monoculare e l’odometria visivo-inerziale (VIO) per produrre stime della profondità densa con una scala metrica. Questo approccio fornisce una stima accurata della profondità, che può aiutare nella ricostruzione della scena, nella mappatura e nella manipolazione degli oggetti.
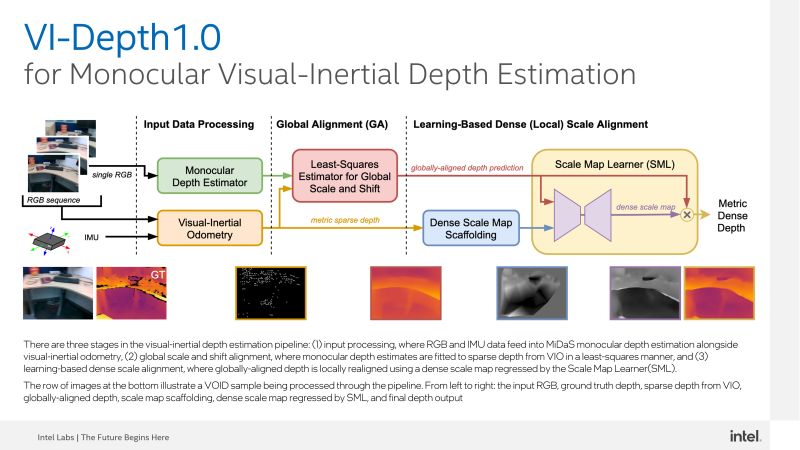
L’integrazione di dati inerziali può aiutare a risolvere le ambiguità nella scala. La maggior parte dei dispositivi mobili contiene già unità di misura inerziale (IMU). L’allineamento globale determina la scala globale appropriata, mentre l’allineamento della scala densa (SML) opera localmente e spinge o trascina le regioni verso la profondità metrica corretta.
La rete SML sfrutta MiDaS come spina dorsale del codificatore. Nella pipeline modulare, VI-Depth combina la stima della profondità basata sui dati con il modello di previsione della profondità relativa di MiDaS, insieme all’unità di misurazione del sensore IMU. La combinazione di fonti di dati consente a VI-Depth di generare una profondità metrica densa più affidabile per ogni pixel in un’immagine.