
da Hardware Upgrade :
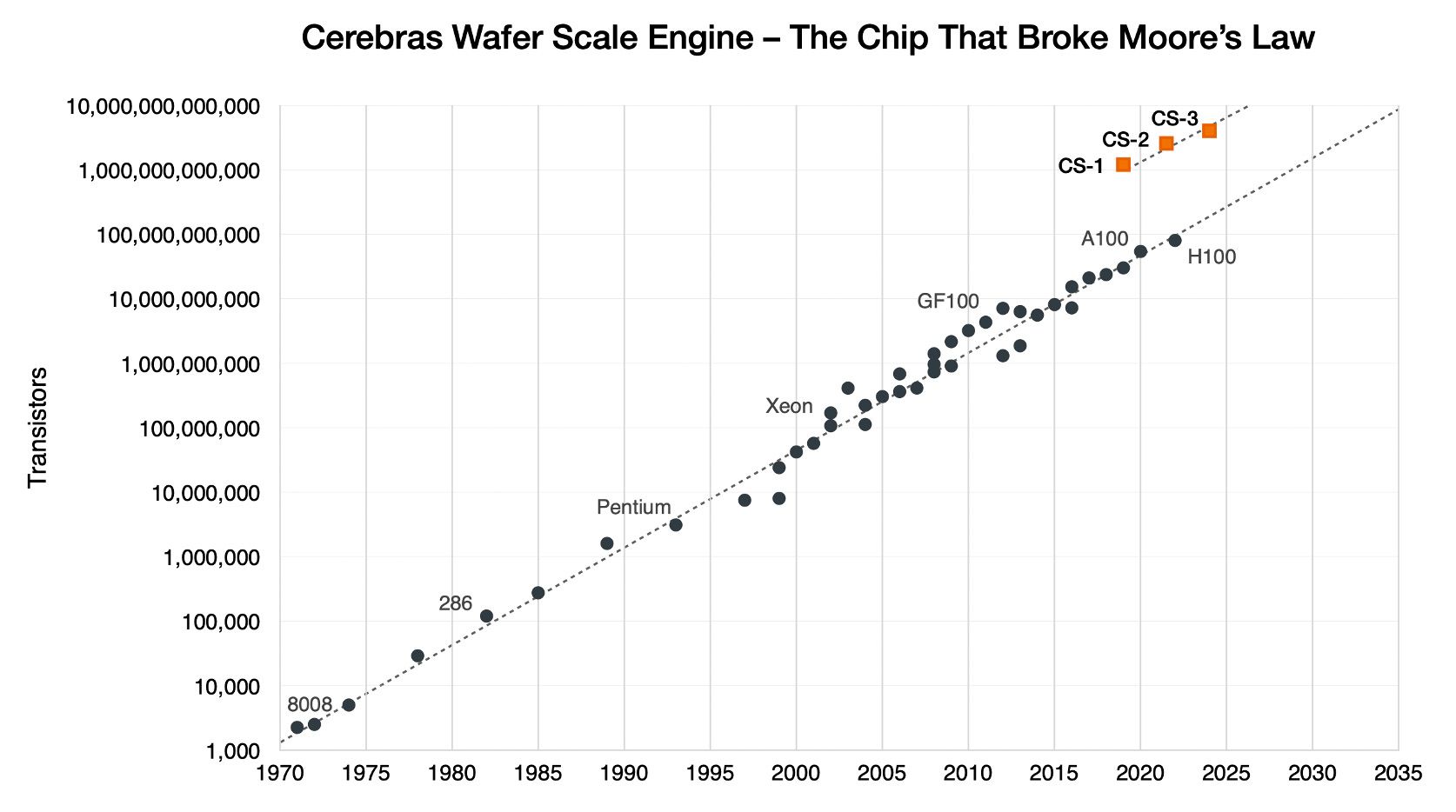
Cerebras Systems ha annunciato Wafer Scale Engine 3 (WSE-3), terza iterazione del processore per l’intelligenza artificiale grande quanto un wafer di chip in silicio – occupa un’area di 46225 mm2.
Il nuovo WSE-3 raddoppia le prestazioni del precedente WSE-2 ma ne mantiene invariati i consumi e il prezzo. “WSE-3 è il chip AI più veloce al mondo”, ha dichiarato senza mezzi termini Andrew Feldman, CEO e co-fondatore di Cerebras.
Il processore della società statunitense nasce per addestrare i più grandi modelli di intelligenza artificiale del settore (fino a 24000 miliardi di parametri) e al suo interno prevede 900.000 core, 50.000 in più del WSE-2 per una prestazione di picco di 125 petaflops (FP16 highly sparse). Tra le altre caratteristiche citate troviamo 4000 miliardi di transistor, il processo produttivo a 5 nanometri di TSMC e 44 GB di SRAM on-chip.
CS-3, il sistema al cui interno vive WSE-3, permette di addestrare “la prossima generazione di modelli più grandi di 10 volte rispetto a GPT-4 e Gemini”. Grazie all’interconnessione SwarmX di nuova generazione si possono connettere tra loro fino a 2048 sistemi CS-3 (contro i 192 di CS-2), attingendo a un massimo di 1,2 PB (petabyte) di memoria esterna MemoryX. L’insieme di 2048 sistemi CS-3, secondo Cerebras, è in grado di raggiungere prestazioni di 256 exaflops con calcoli IA e addestrare Llama2-70B da zero in meno di un giorno.

Rispetto all’acceleratore H100 di NVIDIA, il WSE-3 è circa 57 volte più grande e vanta circa 62 volte le prestazioni “FP16 sparse”. Considerando le dimensioni e il consumo energetico di CS-3, però, sarebbe più corretto confrontarlo con una coppia di sistemi DGX per un totale di 16 NVIDIA H100. In questo caso, il CS-3 è comunque circa 4 volte più veloce, ma solo se si considerano le performance “FP16 sparse”.
Uno dei principali vantaggi di Cerebras è la bandwidth di memoria. Grazie ai 44 GB di SRAM on-chip, l’ultimo prodotto di Cerebras vanta una larghezza di banda della memoria di 21 PB/s, contro i 3,9 TB/s raggiunti dall’acceleratore NVIDIA H100 con memoria HBM3.

Nella sua nota stampa Cerebras afferma che l’addestramento di un modello da 1000 miliardi di parametri su CS-3 è semplice “quanto quello di un modello da un miliardo di parametri sulle GPU”. Inoltre, un sistema CS-3 richiederebbe il 97% di codice in meno rispetto alle GPU per gli LLM (Large Language Model). “Un’implementazione standard di un modello di dimensioni GPT-3 ha richiesto solo 565 righe di codice su Cerebras: un record per il settore”.

Cerebras afferma di avere già un considerevole arretrato di ordini per CS-3 da evadere. In particolare, la società punta l’attenzione sulla partnership con G42, realtà impegnata nel campo dell’IA degli Emirati Arabi Uniti.
Dopo aver creato insieme i supercomputer Condor Galaxy 1 (CG-1) e Condor Galaxy 2 (CG-2), le due società hanno annunciato i lavori su Condor Galaxy 3 (CG-3), sistema che sarà installato a Dallas, Texas. “Condor Galaxy 3 sarà costruito con 64 sistemi CS-3 per una potenza di 8 exaflops con calcoli IA” si legge nella nota che fissa l’operatività nel corso del Q2 2024.
Infine, Cerebras ha annunciato di aver collaborato con Qualcomm per sviluppare una piattaforma IA congiunta per la formazione e l’inferenza. “I modelli addestrati sul CS-3 utilizzando le nostre caratteristiche architettoniche esclusive come la sparsità non strutturata possono essere accelerati sugli acceleratori di inferenza Qualcomm AI 100 Ultra. Nel complesso, il throughput dell’inferenza LLM è fino a 10 volte più veloce”, conclude la società.